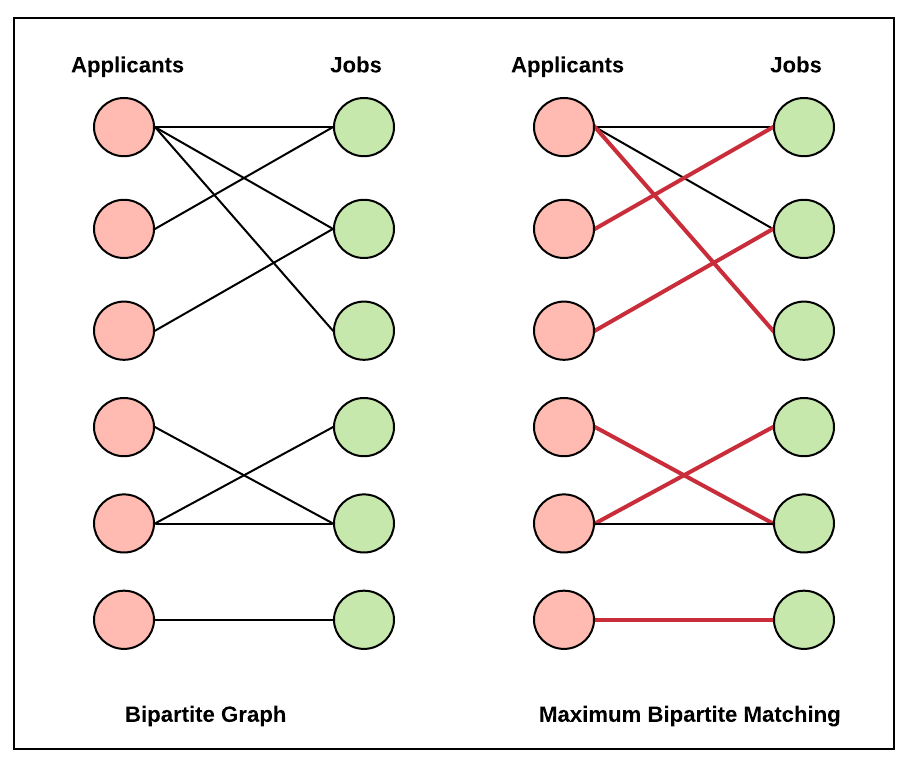
The author Karp, Vazirani, and Vazirani introduce a bipartite graph model G=(U∪V,E),
where U is given offline and V arrives online [KVV90].
The online algorithm must irrevocably match each arriving vertex v∈V to an unmatched neighbor in U or leave it unmatched.
The offline optimal is defined as the maximum matching in G.
The competitive ratio is defined as the expected size of the matching produced by the online algorithm divided by the size of the offline optimal matching.
Ratio=ALG/OPT
Online Stochastic Matching Problem
In the online matching problem with stochastic rewards, every edge (u,v) also has an associated probability of success puv.
When a new vertex v∈V arrives online, the algorithm either chooses not to assign it at all, or assigns it to one of its neighbors (these are the available options).
If v is assigned to u∈U using the edge (u,v), a Bernoulli experiment is performed and the edge (u,v) becomes a successful assignment with probability puv.
In successful assignment case, we say that u was successful and remove it from the set of available vertices.
On the other hand, if the assignment (u,v) is not successful, u remains available and a neighbor of u that arrives later in the online order can be assigned to u (but v cannot be assigned in the future).
The overall objective is to maximize the expected number of successful vertices u∈U, or equivalently, the expected number of successful assignments.
Vertex-Weighted Stochastic Matching
In the vertex-weighted variant, each offline vertex u∈U has a nonnegative weight wu.
A successful assignment on u yields reward wu and removes u from availability (as before).
The objective becomes maximizing the expected total weight of successful offline vertices:
maxE[u∈U∑wu⋅1{uis matched successfully}].
The unweighted model is the special case wu≡1.
The four probability regimes below (Vanishing/Arbitrary × Equal/Unequal) remain the same; results in recent work typically extend to the vertex-weighted case with essentially the same analyses.
Probability Settings
Vanishing & Equal Probabilities
Vanishing & Unequal Probabilities
Arbitrary/Non-Vanishing & Equal Probabilities
Arbitrary/Non-Vanishing & Unequal
Offline Optimal Benchmark
The Budgeted Allocation Problem
Let G=(U∪V,E) be a bipartite graph where edge (u,v) has weight
puv.
For every vertex v∈V, we assign it to one its neighbors u∈U using
edge (u,v).
The loadLu on a vertex u∈U is defined as the sum of weights of
assigned edges incident on u.
The objective is to maximize ∑u∈Umin(Lu,1).
For technical reasons, we allow fractional solutions, i.e. vertex v∈V
can be assigned to its neighbors u∈U with fractions xuv subject to
∑u∈Uxuv≤1; then Lu=∑u∈Uxuvpuv.
For any instance of the Online Stochastic Matching problem, we define
OPT to be the optimum fractional solution for the corresponding Budgeted
Allocation problem.
The next lemma claims that the value of OPT is at least the expected number
of successes obtained by anyOnline Stochastic Matching algorithm.
Distribution of the Success Threshold (Ө)
Let τ be the round of the first success when repeatedly attempting the same offline vertex u. Then
τ∼Geom(p)(τ=1,2,3,…).
Measure “load” as the cumulative success probability: each attempt adds p. Define
Θ:=p⋅τ.
Hence,
Pr[Θ=tp]=p(1−p)t−1(t=1,2,…)
so Θ only takes values in {p,2p,3p,…}.
A vertex u becomes successful the first time its accumulated load ℓu
reaches or exceeds Θ.
This is exactly the “equivalent threshold view” used by Mehta-Panigrahi.
Basic moments. E[Θ]=1 and Var(Θ)=1−p.
Thus, as p→0, both the mean and the variance tend to 1.
Vanishing limit (p→0).
Viewing the discrete distribution as a continuous-load approximation,
Pr[Θ>x]=(1−p)⌊x/p⌋p→0⟶e−x
i.e., Θ⇒Exp(1).
Consequently, in small-p analyses it is standard to model each offline
vertex’s threshold as an independent Exp(1) random variable.
Unequal but small probabilities.
If the edge success probabilities puv differ but are all small, we still
measure load as the sum of allocated success probabilities.
In this continuous-load coordinate, the threshold is well-approximated by
Exp(1); each attempt just increments the load by the
corresponding puv instead of a fixed p.
Definition of Competitive Ratio
Let Nu denote the set of neighbors of an offline vertex u.
For the unweighted case, the competitive ratio is E[ALG]/OPT.
For the vertex-weighted case, the competitive ratio is E[ALGw]/OPTw.
A convenient upper bound/benchmark is the (configuration) LP relaxation; a simple edge-based LP that suffices for exposition is:
Here xuv is the (fractional) probability of attempting (u,v), all
wu≡1 recovers the unweighted benchmark.
Eqn. (1) states that the expected load of each offline vertex u is upper
bounded by 1, because it is upper bounded by the expectation of the threshold
θu, which equals 1. (this uses the Law of Total Probability)
Eqn. (2) is a standard capacity constraint: each online vertex v can be
matched to at most one offline neighbor.
Following the vertex-weighted model of Mehta and Panigrahi [24], we will
consider the optimal objective of the above LP relaxation as the benchmark.
Configuration LP
For any S⊆Nu, let pu(S)=min{∑v∈Spuv,1}.
Consider the following offline-side configuration LP:
From an offline optimization viewpoint, as p, the upper bound of success
probabilities, tends to zero, the configuration LP is equivalent to the
standard matching LP in the following sense.
First, the matching LP can be reinterpreted as to maximize
u∈U∑wu⋅min⎩⎨⎧v:(u,v)∈E∑puvxuv,1⎭⎬⎫
subject to only Eqn. (2) and (3).
On one hand, any feasible assignment of the configuration LP corresponds to a
feasible assignment of the matching LP with
xuv=S∈Nu:v∈S∑xuS.
Comparing the objectives of the LPs, the matching LP objective is weakly
larger because min{z,1} is concave.
On the other hand, given any feasible assignment of the matching LP, we can
sample an integral matching via independent rounding, i.e., match each online
vertex v to a neighbor that is independently sampled according to
xuv ‘s.
Then, it gives an integral assignment of the configuration LP: xuS=1 for
the subset S of neighbors matched to u in the independent rounding, and 0
otherwise.
Further, by standard concentration inequalities (and union bound), the load of
each vertex u is at most its expected load, which is at most 1 due to
Eqn. (1), plus an additive error that diminishes as p tends to zero.
Hence, the optimal of the configuration LP is at least that of the matching LP
less a term that diminishes as p tends to zero.
The corresponding dual LP of the configuration LP is the following:
Approximate dual feasibility: For any u∈U and any S⊆Nu,
E[αu+v∈S∑βv]≥Γ⋅wu⋅pu(S)
Analyses
Let ℓu denote the load of an offline vertex u∈U, Θ be the vector of Θu for all u∈U, and let Θ−u denote the entire vector Θ except Θu.
For any fixed (n−1)-dimensional vector θ−u, let ℓu∞(θ−u) be the load on vertex u when Θ−u=θ−u and Θu=∞ (i.e., in the “phantom world” where u never succeeds).
Dual Assignment
Note that u‘s load increases over time; let ℓu denote the current load in the following discussion.
For some non-decreasing functionf:R+↦R+ to be determined in the analysis, we maintain the dual assignment as follows:
Initially, let αu=0 for all u∈U.
On the arrival of an online vertex v∈V and, thus, the corresponding dual variable βv:
(a) If v is matched to u∈U, increase αu by p⋅f(ℓu) and let βv=p(1−f(ℓu)).
(b) If v has no unsuccessful neighbor, let βv=0.
Let F(ℓ)=∫0ℓf(z)dz denote the integral of f. Note that we have αu=F(ℓu) in the limit as p tends to zero.
Contribution from αu.
We now proceed to prove approximate dual feasibility using the above characterization. First, consider the contribution from the offline vertex u.
_For any thresholds θ−u of offline vertices other than u and the corresponding ℓu∞:_
Eθu[αu∣θ−u]≥∫0ℓu∞e−θuf(θu)dθu.
By the above characterization, u‘s load equals ℓu∞ when θu≥ℓu∞, and equals θu when 0≤θu<ℓu∞. Further, recall that αu=F(ℓu) and that θu∼Exp(1). We get that:
Proof. By the above characterization, all vertices v∈S are matched to neighbors with load at most ℓu∞ at the time of the matches when θu≥ℓu∞. This happens with probability e−ℓu∞ and contributes:
e−ℓu∞pu(S)⋅(1−f(ℓu∞)),
to the expectation in the lemma.
Similarly, all vertices v∈S, except for p−1(ℓu∞−θu) of them, are still matched to neighbors with load at most ℓu∞ at the time of the matches when 0≤θu<ℓu∞.
In the Stochastic Balance algorithm, each online vertex is matched to the unsuccessful neighbor with the least load, so only the overflow load ℓu∞−θu exceeds θu and causes u to become successful.
First, note that the z+ operation effectively restricts the second integration in the above equation to be from max{0,ℓ−p} to ℓ. This allows us to simplify by splitting into two cases.
Case 1: When 0≤p<ℓ, we need:
∫0ℓe−θf(θ)dθ+(1−f(ℓ))(e−ℓ+p−e−ℓ)≥Γ⋅p(Case-I)
Case 2: When 0≤ℓ≤p, we need:
∫0ℓe−θf(θ)dθ+(1−f(ℓ))(1−ℓ+p−e−ℓ)≥Γ⋅p(Case-II)
Then, we show that the worst-case scenario occurs when there is a unit mass of online neighbors, i.e., when p=1.
For Case-II with p=1, we note:
1−f(ℓ)≤1−f(0)≤Γ
So the lemma follows. Hence it suffices to solve the following simplified differential inequalities subject to the boundary condition that f(0)=1−Γ.
For any ℓ>1, we need (Case-I with p=1):
∫0ℓe−θf(θ)dθ+(1−f(ℓ))(e−ℓ+1−e−ℓ)≥Γ(ℓ>1)
while for any 0≤ℓ≤1, we need (Case-II with p=1):
∫0ℓe−θf(θ)dθ+(1−f(ℓ))(2−ℓ−e−ℓ)≥Γ(ℓ≤1)
Right Boundary Condition. To further simplify, we impose a right boundary condition that it suffices to ensure that f(ℓ)=1−e1 for ℓ≥1.
Lemma. Suppose f:[0,1]↦R+ is a non-decreasing function such that f(0)=1−Γ, f(1)=1−e1, and the inequality for ℓ≤1 holds for any 0≤ℓ≤1. Then, the extension of f such that f(ℓ)=f(1)=1−e1 for all ℓ>1 satisfies the dual feasibility inequality for all ℓ≥0.
Proof. By the assumption of f, it suffices to show that the difference between the LHS of the inequality for ℓ>1 with any ℓ>1 and that when ℓ=1 is non-negative. The difference is (recalling that f(ℓ)=1−1/e for all ℓ≥1):
As a result, it suffices to find a non-decreasing function f subject to the boundary conditions f(0)=1−Γ and f(1)=1−1/e, such that the inequality for ℓ≤1 holds for any 0≤ℓ≤1. Solving this differential inequality for f gives,
f(x)=h(x)1(1−e1+∫x1(1−e−y)g(y)h(y)dy)
where g(x)=2−x−e−x1, and h(x)=exp(∫x1g(z)dz).
To conclude, we obtain the function f(x) described above. Thus Γ=1−f(0)≈0.576. □
Worst case scenario analysis
Online Matching on the Z-shaped Bipartite Graph — Full Derivation (Random Seat Selection)
This note gives a complete, self-contained derivation for the model:
Each online node vj (where j∈{1,…,n}) draws Nj∼Pois(1) and then picks
min(Nj,#AvailableNeighbors)uniformly at random without replacement
from its currently available neighbors. We analyze the expected total matches on the
triangular (“Z-shaped”) bipartite graph with the G(n,k) structure.
Model
Offline nodes: u1,u2,…,un, each with capacity 1.
Online nodes: v1,v2,…,vn, arriving in order.
Adjacency:
If j≤k: online node vj connects to offline nodes {uj,uj+1,…,un}.
If j>k: online node vj connects only to offline node uj (diagonal).
Processing rule:
Independently draw Nj∼Pois(1).
At the moment online node vj is processed, let Sj be the set of its currently available
neighbors and Rj=def∣Sj∣ .
Pick Yj=min(Nj,Rj) offline nodes uniformly at random without replacement in Sj
and occupy them.
Let Mn,k be the total number of matched offline nodes when all n online nodes have been processed.
Phase Split
We split the process into two phases:
Phase A: online nodes vj for j=1,…,k (suffix online nodes).
Phase B: online nodes vj for j=k+1,…,n (diagonal online nodes).
Total matches:
Mn,k=M(A)+M(B).
Phase A — Per-online-node “hit probability” (discrete hazard)
Fix an online node vj with j≤k. Conditional on the history (all randomness before online node vj is processed),
the set Sj of available neighbors has size Rj.
By symmetry of uniform without replacement within Sj,
each offline node ui∈Sj has the same conditional hit probability
hj=Pr(online node vj selects a given ui∈Sj∣Sj)=RjE[min(Nj,Rj)∣Sj].
With-replacement “Poissonization” (often used for occupancy):
For large Rj the without/with-replacement difference is O(Rj−2), which is negligible
in our large-n limit (it contributes only o(1) after summing across online nodes).
Key single-online-node conservation:
the total hit probability online node vj “sprays” across its available set is
ui∈Sj∑hj=Rj⋅hj=E[min(Nj,Rj)∣Sj]=1−Pr(Nj≥Rj∣Sj)≈1(since typically Rj≫1).
Phase A — Mass Transport (double counting / conservation of expectation)
Let U be a uniformly random offline node in {u1,…,un}, sampled independently of the process.
Define the cumulative Phase-A hazard on offline node U by
HU(A)=defj=1∑khj1{U∈Sj}.
Taking expectations and swapping sums (double counting):
Intuition: each of the first k online nodes contributes about 1 unit of “risk” across offline nodes,
so per offline node the average Phase-A hazard is k/n (up to o(1)).
Non-uniformity note. For a fixed offline node ui,
only online nodes vj with j≤min{i,k} can hit it, so its mean Phase-A hazard is
μi≈min{i,k}/n (not uniform). We will use this refined view below.
Phase A — Survival probability and expected matches
Conditional on the process, the probability that offline node U survives Phase A (remains empty) is
j=1∏k(1−hj1{U∈Sj}).
When each hj is small (here hj=O(1/Rj)=O(1/n) for almost all rows),
j∏(1−hj)=exp(−j∑hj+O(j∑hj2))≈e−HU(A),
and ∑jhj2=o(1). Concentration (bounded differences / Azuma–McDiarmid) further pins
HU(A) near its mean, hence
E[Phase-A survival of U]=E[e−HU(A)]=e−E[HU(A)]+o(1)=e−k/n+o(1).
Therefore,
E[M(A)]=n−ne−k/n+o(n).
Refined (non-uniform) Phase-A sum. If you want the offline-node-by-offline-node form,
With vs. without replacement: the difference in a single online node is O(Rj−2),
and across k=O(n) online nodes the cumulative effect is o(1) in normalized expectation.
Concentration: Why can we replace E[e−HU(A)] with e−E[HU(A)]?
The key is that HU(A)=∑j=1khj1{U∈Sj} concentrates tightly around its mean.
Bounded differences property. When online node vj arrives:
Suppose Rj≥n−j+1 (almost always true in Phase A)
The discrete hazard hj≈1/Rj is the probability that vj hits any specific offline node in Sj
Changing vj‘s random choice affects HU(A) by at most 1/Rj (it can only “hit” U with probability ≈1/Rj)
After summing across Nj≤L=O(logn) attempts (since Nj∼Pois(1) is typically small), we get Lipschitz constant:
cj≤n−j+1CL≤n(1−α)CL,where L=O(logn)
Applying Azuma–McDiarmid. Define Mj=E[HU(A)∣v1,…,vj processed] as a Doob martingale. The bounded differences give:
j=1∑kcj2≤n2C2L2j=1∑k(1−nj−1)21=O(n(logn)2)
By the Azuma–McDiarmid inequality (for martingales with bounded differences), for any ε>0:
Setting ε=Θ(n−A) for any A>0 (say A=1/2), the deviation probability is exponentially small. Therefore HU(A)=E[HU(A)]+O~(1/n) with high probability, which justifies:
E[e−HU(A)]=e−E[HU(A)]+o(1)=e−k/n+o(1)
Refined Phase-A formula using Pr(survive at ui)≈e−min{i,k}/n
yields
while the extreme cases k=0 and k=n both give E[M]/n≈1−e−1.
Yet another Primal Dual Analyses
Analyses for α
The same as previous: For any thresholds θ−u of offline vertices other than u and the corresponding ℓu∞.
In the matching process, each online vertex contributes an infinitesimal load p to αu, so the incremental change is Δαu=p⋅f(θu).
However, this increment only occurs when vertex u has not yet succeeded (i.e., when θu>ℓu), which happens with probability Pr[θu>ℓu]=e−ℓu.
Aggregating these infinitesimal updates over the entire process, the total increase in αu is the probability that αu exceeds a threshold θ weighted by f(θ):
Fix θ−u and let θu=∞ (phantom world for some fantasy description).
S be any feasible set of online vertices that S⊆N(u).
Let ℓu∞ be the final load on u.
Define R=∣S∣, there are R events that each online vertex v∈S is matched to some offline vertex or may not be matched.
In each event, βv=p⋅(1−f(ℓv)) if matched, and 0 otherwise.
ℓv means in this world, the load of the offline vertex that v is matched to when this event happened. Doesn’t have to be u
When an online vertex v∈S is matched in the algorithm:
The algorithm greedily selects the neighbor with the minimum current load among all available neighbors.
If offline vertex u is still available at this moment with load ℓu≤ℓu∞, then v matched neighbor’s load satisfies ℓv≤ℓu.
Since the dual assignment function f is non-decreasing (monotone), we have:
βv=p(1−f(ℓv))≥p(1−f(ℓu))
The events in this world occur in a continuous, infinite sequence when pushing the limit. As the load on vertex u gradually increases from 0 to θ, many events occur. Each event corresponds to an online vertex v∈S being matched (to some offline vertex, not necessarily u).
Define the cumulative distribution function that tracks which online vertices from S have been matched by the time u‘s load reaches ℓu:
MS(ℓu):=p⋅∣{v∈S∣v is matched when u’s load≤ℓu}∣
The Lebesgue–Stieltjes measureμS is defined as:
μS((a,b]):=MS(b)−MS(a),0≤a<b≤ℓu∞
This measure captures the “mass” of online vertices from S that are matched during the period when u‘s load grows from a to b.
Properties when vanishing probabilities (p→0):
When the probabilities are vanishing, μS is absolutely continuous with respect to the Lebesgue measure, and there exists a Radon-Nikodym derivative (density function):
φS(ℓu):=dℓudμS(ℓu),φS(ℓu)=0 for ℓu>ℓu∞,MS(ℓu)=∫0ℓuφS(z)dz,∫0ℓu∞φS(ℓu)dℓu=p⋅R.
Note that MS(ℓu∞)≥pu(S) (because pu(S)=min{∑v∈Sp,1}, and in the “phantom world” where u is always available, MS(ℓu∞)=p⋅∣S∣≥pu(S)).
Intuitively, φS(ℓ) is the “load density” from S at load ℓ (it describes the rate at which online vertices from S are being matched when u‘s load is at ℓ). Note that ℓu∞ is the total load on u when θu=∞ in this phantom world.
When a micro-event happens and u‘s load is ℓu, the contribution is:
βv=p⋅(1−f(ℓv))≥p⋅(1−f(ℓu))(since ℓv≤ℓu)
Now we analyze when each θu∼EXP(1).
When θu≥ℓu∞ (warm-up)
All online vertices v∈S are matched to neighbors, so the total contribution is:
Instead of “when does u succeed in the real world,” we use “when does u succeed in the phantom world at the corresponding arrival,”
which gives each arrival a corresponding “phantom sequence degree” C(τ).
MS(θ)=MS(θu)(θ) when θu≥ℓu∞.
Copy-graph viewpoint. In the [HZ20] paper’s alternative view, fixing thresholds θu turns each offline vertex u into p−1θu copies (u,0),(u,p),…,(u,θu−p). Each online vertex always matches a copy with the smallest load (ties broken lexicographically). Changing θu just adds/removes copies of u.
Prefix of the process does not change. Compare the “phantom world” (∞,θ−u) with the “θu-world” (θu,θ−u).
Up to any load level ℓ≤θu, the set of available copies and their loads are identical in the two worlds, because any copies that differ appear only above level θu.
Hence the greedy rule (“pick smallest-load copy, lexicographic tie-break”) makes the same choices in both worlds up through load ℓ.
Formally, in the alternating-path argument used to compare two instances that differ by one extra copy of u at a higher level, the paper notes that before the first vertex v∗ that would touch that extra copy arrives, the matchings in the two graphs are identical—this is exactly the needed prefix invariance.
Conclusion. Therefore, the set (and total “mass” p⋅∣⋅∣) of vertices from S that get matched while u‘s load is ≤ℓ is the same in both worlds, giving MS(θu)(ℓ)=MS(ℓ) and the equality of the measures on every interval (0,ℓ].
(As a boundary case, if θu≥ℓu∞ then the two worlds coincide for the entire run, so the equality holds on (0,ℓu∞] outright.)
Done.
In the [HZ20] paper, by using Structural Lemma for Equal Probabilities, we have:At most p−1(ℓu∞−θu) online vertices differ in being matched between the two worlds.
Splitting S into S1 and S2
In the ”θ=∞ phantom world”, we decompose S into:
S1: those online vertices that are ultimately matched to u;
S2: those online vertices that are ultimately matched to other offline vertices.
When the threshold is reduced to θu, only decisions related to contacts with u will change, so the “affected flow” mainly comes from S1.
The alternating path “splits off” this portion of the flow and reroutes it to other offline vertices or leaves it unmatched.
Meanwhile, S2 remains equivalent unchanged (possibly only with some vertices from S1 replacing vertices from S2 in their original positions, i.e., identities are swapped, all the offline vertices which originally be matched would still be matched, even if their matched online parterer nodes have changed).
This is precisely the origin of “at most loss of p per p-layer”, which accumulates to “at most loss of 1 per unit ℓ”.
The corresponding formal tool is the alternating-path comparison in the paper together with the structural lemma that “at most 1 vertex crosses the threshold”.
Descending Density Lemma
Fix θ−u.
For any interval (a,b]⊆(θu,ℓu∞], we have
(μS−μS(θu))((a,b])≤b−a.
Equivalently (viewing this as a Lebesgue measure λ((a,b])),
(μS−μS(θu))+≤λon (θu,ℓu∞].
If p→0 with bounded densities (Radon–Nikodym derivatives) φS=dℓdμS, φS(θu)=dℓdμS(θu), then for almost every ℓ∈(θu,ℓu∞],
0≤φS(ℓ)−φS(θu)(ℓ)≤1.
Proof Intuition (discretize to each p-layer → alternating path → sum).
This states that ”φS(θu) relative to φS decreases at ℓu∞≥ℓ>θu, and the reduction is bounded by a constant 1—a strictly ‘level-by-level’ statement.”
Let the “phantom world” be G(∞,θ−u) and the “θu-world” be G(θu,θ−u).
Consider ℓt:=tp where we think of ℓ decreasing from ℓu∞ down to ℓ=θu.
For each discrete layer level, define
Gt−1=G(ℓt,θ−u),Gt=G(ℓt−p,θ−u),
which differs only by one copy (u,ℓt−p).
Let the top vertex in the many copies that appear in Gt−1 be v∗.
Before v∗ arrives, the matchings in the two graphs are completely identical; it is only after v∗ arrives that a certain alternating path is transmitted.
For each layer-level interval (ℓt−p,ℓt]⊆(θu,ℓu∞], before all decisions reach agreement up to v∗ arrives, this only affects at most one vertex in this layer-level interval being counted into “S-quality at this layer” or “load less than this layer’s matching S-quality”.
Therefore,
(μS−μS(θu))((ℓt−p,ℓt])≤p.
Cutting (θu,ℓ] into pℓ−θu such child intervals and summing, we obtain
(μS−μS(θu))((θu,ℓ])≤ℓ−θu,∀ℓ≤ℓu∞,
which is the “measure version” above.
Taking p→0 under absolute continuity substitution, we obtain the “density version” with pointwise upper bound φS(ℓ)−φS(θu)(ℓ)≤1 when ℓ∈(θu,ℓu∞].
This is EXACTLY the same as the [HZ20] paper’s beta’s RHS scaling.
Three examples for building intuition
We first suppose pu(S)=1,R=∣S∣=1/p for simplicity.
Example 1:
In phantom world, all of S ‘s mass into the last unit of load on u.
In Real ( θ-) world: By prefix invariance, up to load ℓ≤θ the evolution matches the phantom world.
To obtain the most pessimistic real-world mass profile for ∑β, we simply delete all mass above θ.
a continuous block of unit density on the interval ( a,ℓu∞ ), and
an atomic mass at ℓ=ℓu∞ of size σ:=1−(ℓu∞−a).
(Feasibility: 0≤ℓu∞−a≤1 so that σ∈[0,1].)
In the real ( θ-) world: by prefix invariance, up to load ℓ≤θ the evolution agrees with the phantom world; to obtain the most pessimistic real-world profile for ∑β, we truncate the continuous block above θ, while the atom at ℓu∞ is preserved for every θ (no-atom-loss).
Measure-level definitions. Let
μS=unit density on (a,ℓu∞)λ↾(a,ℓu∞)+atom at ℓu∞σδℓ=ℓu∞,σ=1−(ℓu∞−a).
For each θ≥0, define the pessimistic real-world measure
Fix ℓu∞>0 and the thresholds θ−u. Let f:[0,∞)→[0,1] be nondecreasing, and set g(ℓ):=e−ℓ(1−f(ℓ)), which is nonincreasing on [0,ℓu∞].
Let μS be any feasible cumulative measure on (0,ℓu∞] with total mass
MS(ℓu∞)=μS((0,ℓu∞])=1
and write its Radon-Nikodym decomposition μS=μac+μsing with density ϕ=dℓdμac∈[0,1] a.e. on (0,ℓu∞].
This is equivalent to using y=1 to horizontally cut μS: the upper part is μsing, and the lower part is μac.
Denote L:=μac((0,ℓu∞])=∫0ℓu∞ϕ(ℓ)dℓ∈[0,1].
Then the expected β-contribution satisfies
Eθu[v∈S∑βv∣θ−u]≥continuous block ∫ℓu∞−Lℓu∞e−ℓ(1−f(ℓ))dℓ+terminal atom (1−L)(1−f(ℓu∞)).
hint: equality is attained by the following Example 3 shape:
μS⋆=λ↾(ℓu∞−L,ℓu∞)+(1−L)δℓ=ℓu∞
(unit density on the rightmost length- L interval plus an atom of size 1−L
Since
Eθu[αu∣θ−u]=∫0ℓu∞e−ℓf(ℓ)dℓ
does not depend on μS, the same lower bound (with the same extremizer) holds for the total expectation E[αu+∑v∈Sβv∣θ−u].
Proof
( 0,ℓu∞]. Decompose μS=μac+μsing and set
L:=μac((0,ℓu∞])∈[0,1],σ:=μsing((0,ℓu∞])=1−L.
Step 2 (Lower bound as “continuous + singular” parts).
Using the phantom-time indexing and the standard truncation construction of μS(θ), one obtains the following lower bound (which will be tight for our extremal shapes):
Heuristically: each continuous sliver at level ℓ survives when θu≥ℓ, contributing a factor e−ℓ; whereas atoms cannot be shaved off by truncation (otherwise we would create a singular positive difference), hence every atom contributes (1−f(⋅)) without an extra e−ℓ factor after averaging in θ.
Step 3 (Rearranging the continuous part to the right).
We must minimize ∫g(ℓ)ϕ(ℓ)dℓ subject to ϕ∈[0,1] a.e. and ∫ϕ=L, where g(ℓ)=e−ℓ(1−f(ℓ)) is nonincreasing. A standard Hardy-Littlewood exchange shows that moving any positive mass of ϕ from a smaller ℓ to a larger ℓ does not increase the integral. Iterating these exchanges yields the extremal density
ϕ⋆(ℓ)=1(ℓu∞−L,ℓu∞](ℓ)
whence the minimal continuous contribution is
∫ℓu∞−Lℓu∞e−ℓ(1−f(ℓ))dℓ
Step 4 (Placing the singular mass).
The singular contribution is ∑μsing {x}(1−f(x)). Because 1−f is nonincreasing, this is minimized by concentrating all singular mass at the right endpoint:
x∑μsing {x}(1−f(x))≥σ(1−f(ℓu∞)) with equality by taking μsing =σδℓ=ℓu∞.
Step 5 (Combine and attainability).
Combining Steps 3-4 yields